
On April 2, 2026, Google DeepMind launched Gemma 4, a new family of multimodal open-weight models that sets fresh standards for performance-per-parameter in the open AI ecosystem. The release includes four variants: Gemma 4 31B (dense), Gemma 4 26B A4B (Mixture-of-Experts), plus smaller Gemma 4 E4B and Gemma 4 E2B models optimized for edge and on-device deployment.
Answer first: Gemma 4 delivers state-of-the-art results for its size. The 31B model achieves 85.7% on GPQA Diamond (reasoning mode) in independent testing — the second-highest score ever recorded for an open-weights model under 40B parameters, trailing only Qwen3.5 27B by a razor-thin 0.1%. It does so with remarkable token efficiency, using just ~1.2M output tokens compared to 1.5M+ for close competitors.
This positions Gemma 4 as a direct challenger to larger proprietary and open models from Meta (Llama 4), Alibaba (Qwen), and others, while running efficiently on a single H100 GPU for the larger variants.

What Is Gemma 4 and Why Does the Release Matter in 2026?
Gemma 4 builds on the same research and technology stack as Google’s flagship Gemini 3 models. Unlike previous Gemma versions, the entire family now ships under the permissive Apache 2.0 license, enabling unrestricted commercial use, fine-tuning, and redistribution without earlier restrictions.
Key technical highlights:
Multimodal native support — Text, image, and video inputs across the family.
Context windows — Up to 256K tokens for the 31B and 26B A4B models; 128K for the smaller edge-optimized variants.
Architectures — Dense (31B) and MoE (26B active parameters) for the larger models; highly efficient designs for E-series edge models.
Deployment flexibility — From smartphones and edge devices (E2B/E4B) to single-GPU workstations and cloud TPUs.
Google positions Gemma 4 as “byte for byte, the most capable open models,” emphasizing intelligence-per-parameter over raw scale. Early Arena.ai rankings place the 31B variant as the #3 open model overall and the 26B MoE as #6, with user preference scores outperforming significantly larger models in blind tests.
Gemma 4 Benchmark Performance: How It Compares to Leading Models
Independent evaluator Artificial Analysis (@ArtificialAnlys) provided some of the first detailed third-party numbers shortly after launch. Their GPQA Diamond results (scientific reasoning) stand out for both capability and efficiency.
GPQA Diamond (Reasoning mode):
Gemma 4 31B: 85.7% (2nd highest for open <40B params)
Qwen3.5 27B: 85.8% (1st)
Gemma 4 26B A4B: 79.2% (ahead of gpt-oss-120B at 76.2%)
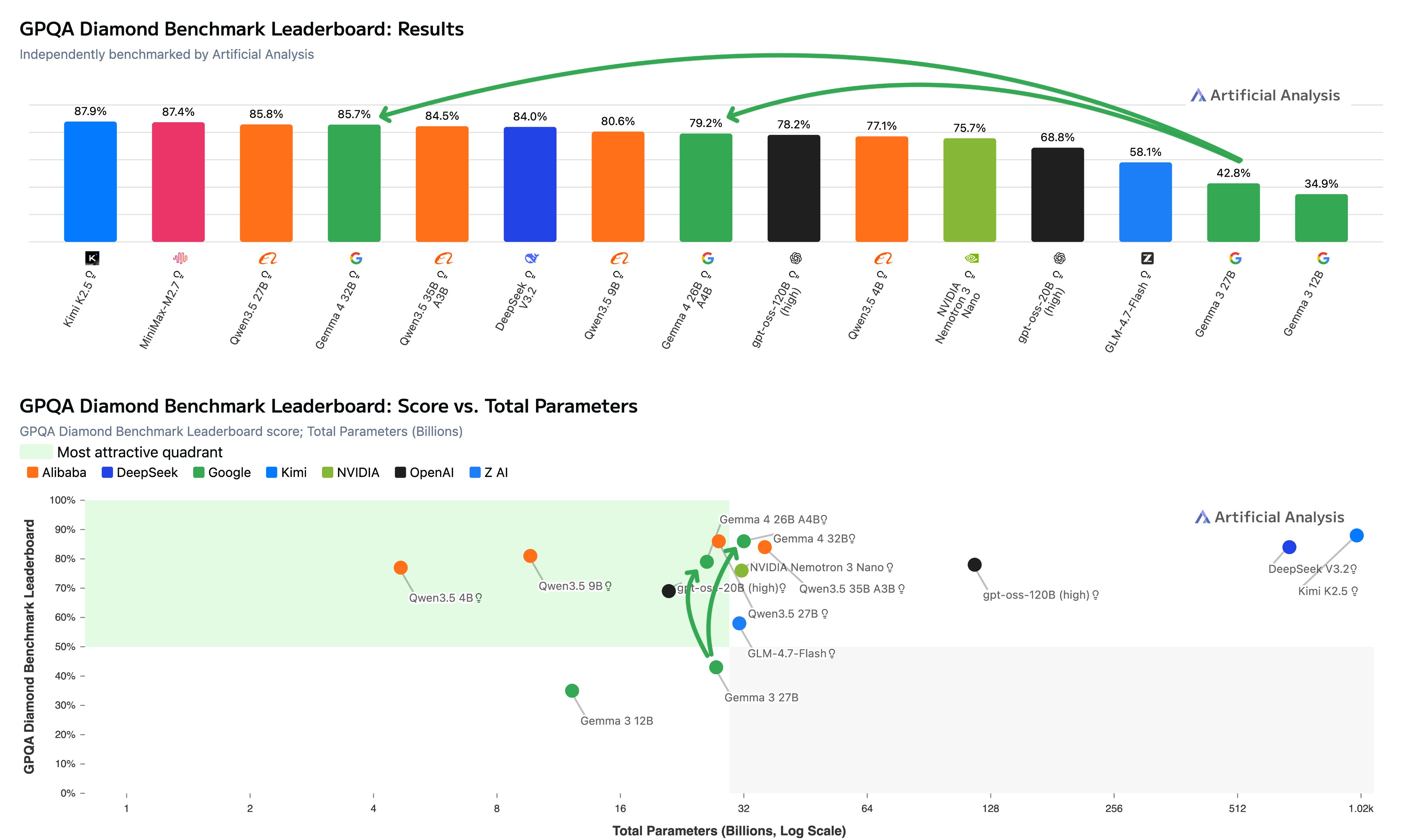
The 31B model reaches its score using ~1.2M output tokens — notably fewer than Qwen3.5 27B (~1.5M) and Qwen3.5 35B A3B (~1.6M). This token efficiency translates to lower inference costs and faster reasoning chains in agentic workflows.
Google’s own model card and blog highlight additional strengths:
Strong gains on MMLU-Pro, AIME 2026, BigBench Extra Hard, and multimodal benchmarks (vision + long-context tasks).
The family forms an impressive Pareto frontier when plotting performance versus model size — meaning better quality at every scale point compared to prior open models.
Early community and leaderboard signals (as of April 3, 2026) show:
Gemma 4 31B ranking competitively on LMSYS Arena / LMArena text leaderboards, sometimes preferred over larger Qwen3.5 variants and approaching Claude 4.5 Sonnet-level user votes in certain categories.
Coding, math, and agentic capabilities benefit from the underlying Gemini 3 tech, enabling multi-step planning and tool use without heavy fine-tuning.
Compared to predecessors, Gemma 4 represents a clear generational leap over Gemma 3 (whose largest variant was 27B). It also narrows the gap with closed models while remaining fully open-weight and now fully open-source.
Comparison Table: Gemma 4 vs. Key Competitors (Selected Benchmarks)
Benchmark | Gemma 4 31B | Gemma 4 26B A4B | Qwen3.5 27B | Typical Larger Open Models (e.g., 100B+) | Notes |
|---|---|---|---|---|---|
GPQA Diamond (Reasoning) | 85.7% | 79.2% | 85.8% | Varies (often 70-80%) | Token-efficient win for 31B |
Context Window | 256K | 256K | Varies | Up to 1M+ in some | Strong for long-context tasks |
Multimodal (Text+Image+Video) | Native | Native | Limited | Varies | Full support across family |
Inference Hardware | Single H100 | Single H100 | Higher VRAM | Multiple GPUs often required | Edge-to-cloud flexibility |
License | Apache 2.0 | Apache 2.0 | Restrictive in some uses | Varies | Fully commercial-friendly |
(Data synthesized from Artificial Analysis, Google model card, and early April 2026 leaderboards.)
Why Gemma 4 Matters for Developers, Enterprises, and the Open AI Ecosystem
In 2026, the open model landscape is no longer just about who has the biggest parameters. Efficiency, multimodality, and licensing freedom drive adoption for real-world agentic systems, on-device AI, and privacy-sensitive applications.
Gemma 4 shines here:
On-device and edge AI — The E2B and E4B variants deliver up to 4x speed improvements and 60% lower battery usage versus prior generations, making advanced reasoning feasible on phones and embedded hardware.
Agentic workflows — Native support for tool calling, structured outputs, and multimodal reasoning enables autonomous agents that plan, act, and process visual/video inputs offline.
Cost and control — Apache 2.0 removes barriers. Developers can fine-tune, distill, or deploy at scale without usage caps or vendor lock-in.
Multilingual reach — Strong performance across 140+ languages broadens global applicability.
Early adopters on Hugging Face, Google AI Studio, Vertex AI, and inference engines like vLLM report day-zero support with measurable throughput gains (e.g., 15% higher on NVIDIA B200 versus baseline vLLM in some tests).
Practical Implications and Getting Started with Gemma 4
For teams building in 2026:
Use the 31B dense for maximum reasoning depth on GPU servers.
Choose the 26B MoE for a balance of capability and active-parameter efficiency.
Deploy E-series models for mobile, automotive, or low-power edge scenarios.
You can try Gemma 4 immediately in Google AI Studio (larger variants) or the AI Edge Gallery (smaller ones). Full weights are available on Hugging Face with community inference support rolling out rapidly.
Pro tip for SEO/AEO practitioners and AI builders: Models like Gemma 4 accelerate “AI-native” content workflows. Their token efficiency and reasoning strength make them excellent for local RAG, synthetic data generation, and evaluation pipelines that reduce reliance on closed APIs.
FAQ: Gemma 4 Benchmarks and Performance
How does Gemma 4 31B compare to Qwen3.5 on reasoning?
It is nearly tied on GPQA Diamond (85.7% vs 85.8%) but more token-efficient, potentially lowering real-world compute costs in chain-of-thought or agent scenarios.
Can Gemma 4 run on a single GPU?
Yes — both the 31B and 26B A4B models fit on a single H100, making them accessible for smaller teams and researchers.
Is Gemma 4 truly open source?
Yes. The shift to Apache 2.0 marks a more permissive stance than earlier Gemma releases, aligning with community expectations for unrestricted use.
What makes Gemma 4 strong for multimodal tasks?
Native support for text + image + video inputs, combined with long context, allows richer agentic and vision-language applications without separate models.